Personalized Tutorials - UX improvement
When you use a technology application or visit a website providing Fintech services,
you are often presented with a series of detailed tutorials on how to use the features on the app or website, as well as how they work. However, the problem is that if you have
a solid foundation in technology, you may find these tutorials too detailed and filled with
information you already know, making it frustrating to have to click the "skip" button repeatedly.
On the other hand, if you are not tech-savvy or have limited knowledge of technology
you may feel that the standardized tutorials do not provide enough instruction to help you
effectively use the features on the app or website.
A personalized tutorial tailored to your level of technological expertise and usage skills
is a great solution to enhance your experience on technology or Fintech apps and websites.
This is exactly why the "Personalized Tutorials" project was initiated.
Overview
In the tech industry, particularly in Fintech, UX has become a key area of focus for companies looking to improve. The increasing competition in the industry has made it essential for companies to differentiate themselves through personalized experiences that drive customer satisfaction.
However, with the complexity and diversity of product portfolios in the industry, it has become challenging to develop machine learning models that can accurately predict user behavior. The issue lies in the fact that user action data comes in various forms, making it difficult to create a unified data input for these models.
As a result, there is a growing need for Machine Learning (ML) models that can make high-accuracy predictions on unlabeled input datasets and handle diverse types of data. This will enable the application of these models in downstream tasks related to personalized user experience (UX) to improve customer satisfaction.
Executive Summary
User problems landscape
Psych framework
Psych framework is used to visualize the level of emotional satisfaction within the user experience, thereby identifying the phases where the user experience is not yet optimized. This serves as a basis for uncovering the root cause of the increased bounce rate. ‘Required psych’ refers to the necessary motivation for a user to complete a specific task on the product, while ‘Actual psych’ denotes their actual motivation and emotional state while performing that task.
Psych framework is used in conjunction with the scoring rules of the Perfect 1000 system proposed by Fintech Insight
The principle of the Perfect 1000 system scoring is that each user journey begins with an initial psych score of 1000. This psych level is then adjusted—either increased or decreased—based on the motivation or emotional value of the user at each specific task they must complete within their journey.
Scores are recorded on the Required psych scale based on UX data from various Fintech products. This data is highly representative as, in terms of functionality, Fintech products do not vary significantly. The author believes that this value can be utilized for reference purposes. For the values on the Actual psych scale, these are derived from secondary data collected through real user surveys. Due to information security concerns, the author has adjusted some data points in the dataset but has ensured that the goal of practicing skills in developing technological solutions—the main objective of this project—remains intact.
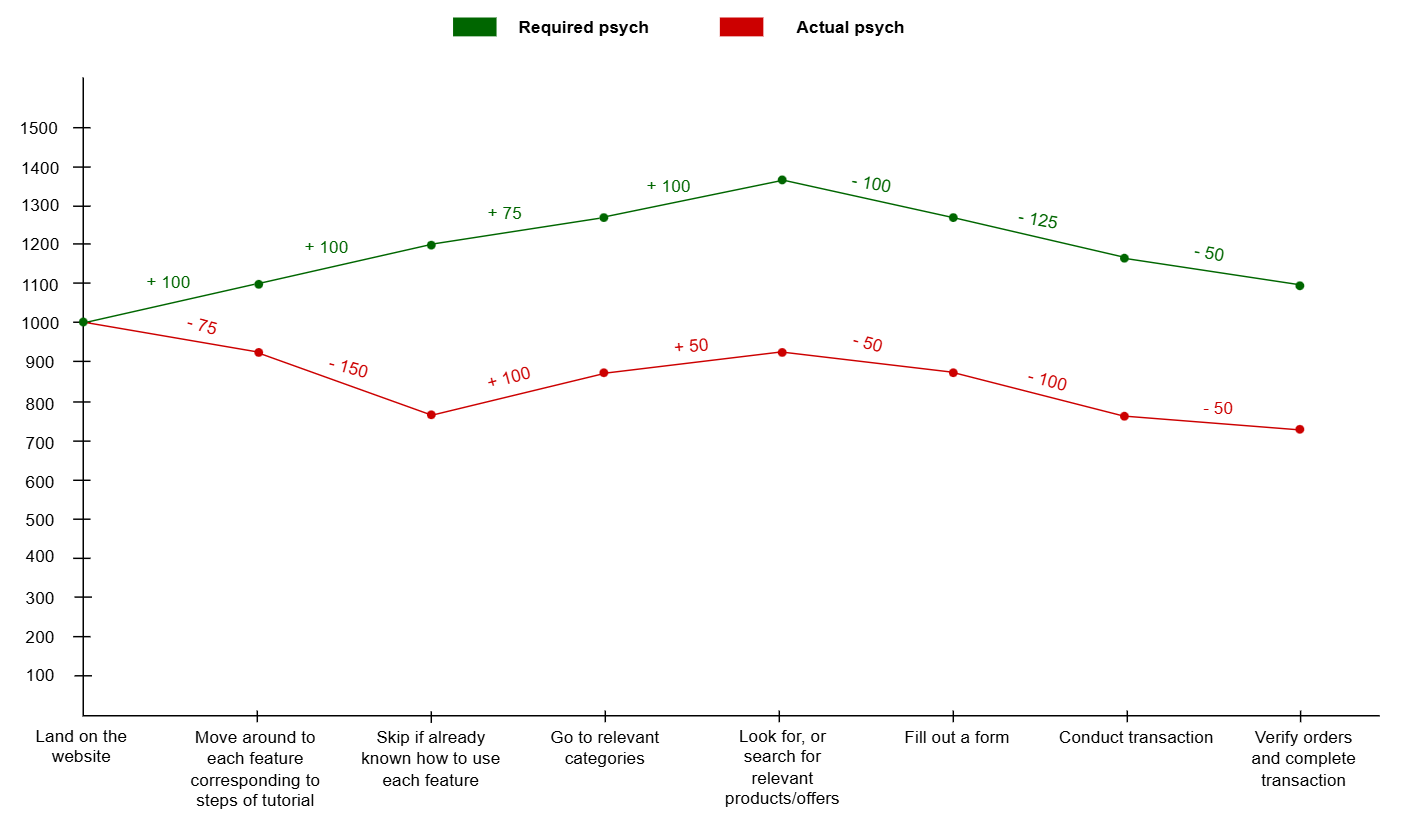
The Required psych and Actual psych curves are nearly identical in shape, with the Actual psych values being lower by approximately 350 to 400 points on average. The only stage where user interaction with the Tutorial diverges in shape is when the Required and Actual curves differ significantly. This indicates a gap between expectations and reality, as the product team anticipates that the tutorial will enhance user interaction with their product and result in high levels of UX satisfaction. However, the opposite is true; interaction with the tutorial not only fails to add positive value to the user’s psych but also brings negative value, suggesting that users are struggling with the tutorial.
The results presented in the Psych diagram indicate that the user interaction phase with the tutorial is likely a contributing factor to negative business outcomes. There is an urgent need for a deeper analysis of the user experience during this phase. What has led users to lose interest in the tutorials? Are they facing frustrations or difficulties? Why is this the case? These are all questions that need to be answered in the Problem Analysis section, which will be conducted using research techniques and user demand elicitation.
Core problem
Tutorials are a vital component of Fintech apps and websites, serving as an introduction to features and providing users with step-by-step instructions on how to effectively use them. However, a common pain point arises when users are presented with generic tutorials that fail to account for their individual level of technical expertise.
When tutorials are not tailored to meet the user's needs, tech-savvy users often find themselves feeling bored, wasting time, and frustrated by the need to constantly click "skip" through content they already know. Meanwhile, non-tech users are left feeling lost and in need of more detailed guidance, highlighting the need for a more personalized and adaptive approach to tutorial design
Problem statement: The mismatch between tutorial content and users' level of familiar with technology can result in a poor user experience, characterized by feelings of frustration, boredom, or confusion, and ultimately, lower levels of user satisfaction on Fintech apps and websites.
Solution development
Objectives
Develop models that can predict the level of familiarity of users with technology to propose customized tutorials accordingly. The models should ensure the following factors:
- Accuracy: model needs to have the ability to perform well with diverse types of data, particularly with unlabeled data.
- Ability to scale up: compatibility with multiple systems from diverse partners
- Simplicity: easy and minimal disruption migration of the solution to partner systems
- Cost efficiency: cost optimization for development and maintenance
Solution
The 'Personalized Tutorials' solution is designed to solve the above-mentioned user problems, enabling Fintech companies to achieve their business goals. There are 2 main phases in solution development:
- Phase 1: Model development, involved several key tasks: models selecting, data preparing, models training, models testing, models improving
- Data wrangling: convert semi-structure data into text-based data
- Build Downstream model: used to predict users familiarity with tech, users actions, and users needs
- Phase 2: Apply models to the process of predicting users' familiarity with technology and recommend customized tutorials for users, and evaluate the effectiveness of the model and business outcomes.
Models selection
Contrastive learning methods are used to build downstream models. This technique is deemed suitable for the 'Personalized Tutorials' solution because self-supervised learning methods can achieve high accuracy with unlabeled input data. Meanwhile, most user action data crawled from apps and websites are unlabeled due to the high diversity in features and product portfolios.
Models building
This is the technical landscape, and the methods for implementing the steps from data wrangling to model construction are detailed below.
Data wrangling
To ensure accuracy, reduce complexity, and increase the applicability of user event data to multiple models, the task of data processing is performed by converting all data into text-based format before importing data into downstream models for prediction.
All input data consists of user actions crawled from apps, websites, or application backends, with diverse data types, including categorical, float, and text, all of which are processed through the BERT model and converted into text-based data for the Contrastive learning model.
Build models
The Contrastive learning model in this project is inspired by the SimCLR framework, developed by Google researchers. The core approach is outlined below:
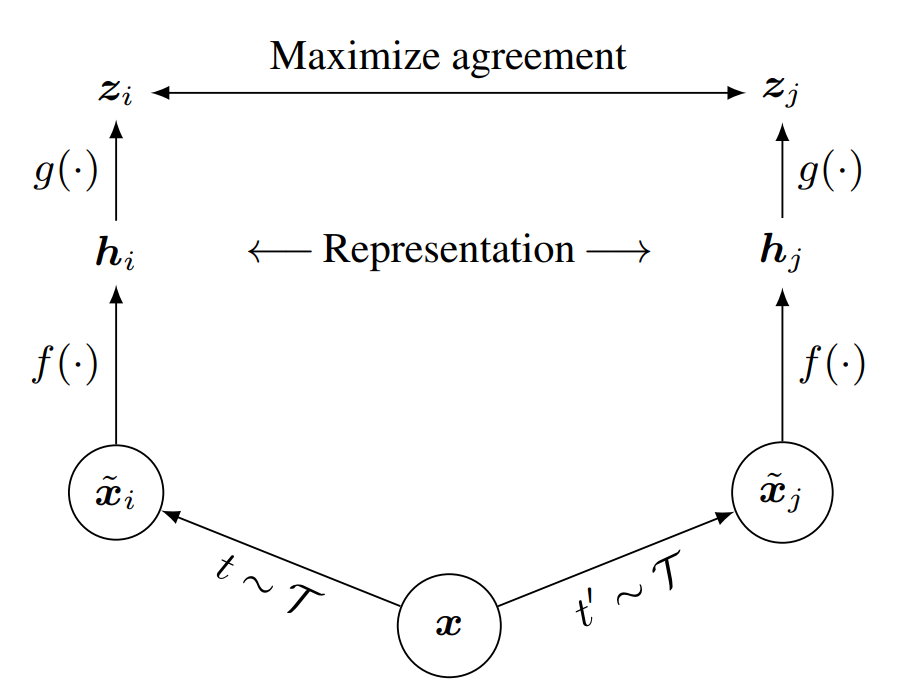
(source: A Simple Framework for Contrastive learning of Visual Representations)
The main objective of the Contrastive learning model is to minimize the distance between the anchor and positive sample, and maximize the distance between the anchor and negative sample.
With input dataset of users actions (or users events), a set of events from a customer is placed as the anchor, with a single event randomly removed from it to serve as a positive sample while other events that don’t occur for that customer are randomly sampled as negative. Contrastive learning tries to minimize the distance between the anchor and positive samples and at the same time maximize the distance to negative samples. At the end, a vector for each symbol in the vocabulary is produced and we aggregate them to get the customer representation.
Data Augmentation
The first crucial step in the Contrastive learning model is Augmentation. At this stage, from each initial data sample, two random views, denoted as x˜i and x˜j, are generated and considered as a positive sample pair. To perform augmentation, the following two methods are proposed to be implemented simultaneously to achieve the best performance:
- Synonym replacement: replaces tokens with similar or synonymous meanings in the text. Utilizes the WordNetTagger() library to leverage Wordnet thesauruses, along with the Natural Language Toolkit (NLTK) library.
from taggers import WordNetTagger
from nltk.corpus import treebank
from tag_util import backoff_tagger
from nltk.tag import UnigramTagger, BigramTagger, TrigramTagger
# Initializing
default_tag= DefaultTagger('NN')
# Initializing training and testing set
train_data= treebank.tagged_sents()[:3000]
test_data= treebank.tagged_sents()[3000:]
taggers= backoff_tagger(train_data, [UnigramTagger, BigramTagger, TrigramTagger], backoff=wn_tagger)
a= tagger.avaluate(test_data)
print("Accuracy: ", a)
The code above trains a POS tagger, which helps identify words that can be replaced during the synonym replacement process.
- Random Insertion/deletion: Randomly inserting or deleting redundant or semantically similar words/tokens that do not include "stopwords" increases the meaning of a sentence/embedding or keeps it semantically unchanged, resulting in the creation of augmented text.
Encoder and projection head
The data encoding operation is performed using the neural network approach. This framework allows the use of various network architectures. In this project, to ensure simplicity and applicability (applicable to multiple models), ResNet is chosen. The result of the encoding function f(.) is the embedding vectors hi, hj, with hi = f(x˜i) = ResNet(x˜i).
Next, a small neural network (specifically, an MLP) is used to map the embedding vectors to the location where the contrastive loss is performed, the output of this function is the embedding map. Represented in the figure as zi, zj.
In addition to the ResNet and MLP models, embedding map can also be generated through the StarSpace model developed by Meta.
Loss function
The loss function is a crucial component that determines the model's learning ability. There are several types of loss functions that can be used, including Triplet Loss, Lifted structured loss, and SimCLR Loss function. In this project, the SimCLR loss function is proposed for application. The loss function is as follows:
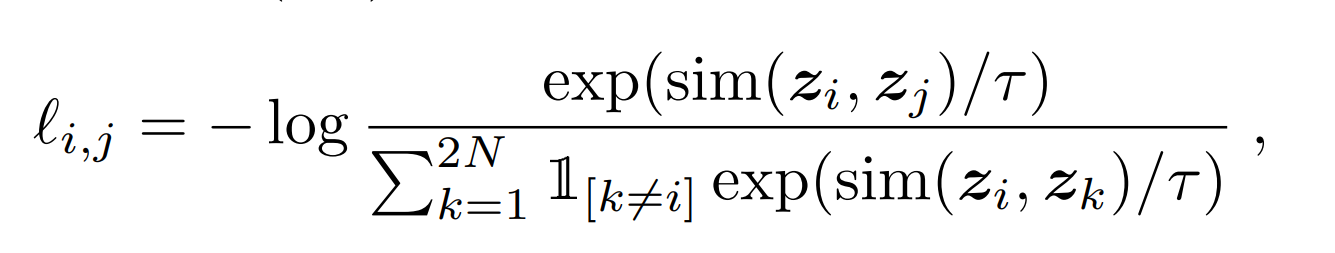
Learn more about SimCLR here
System architecture of the solution
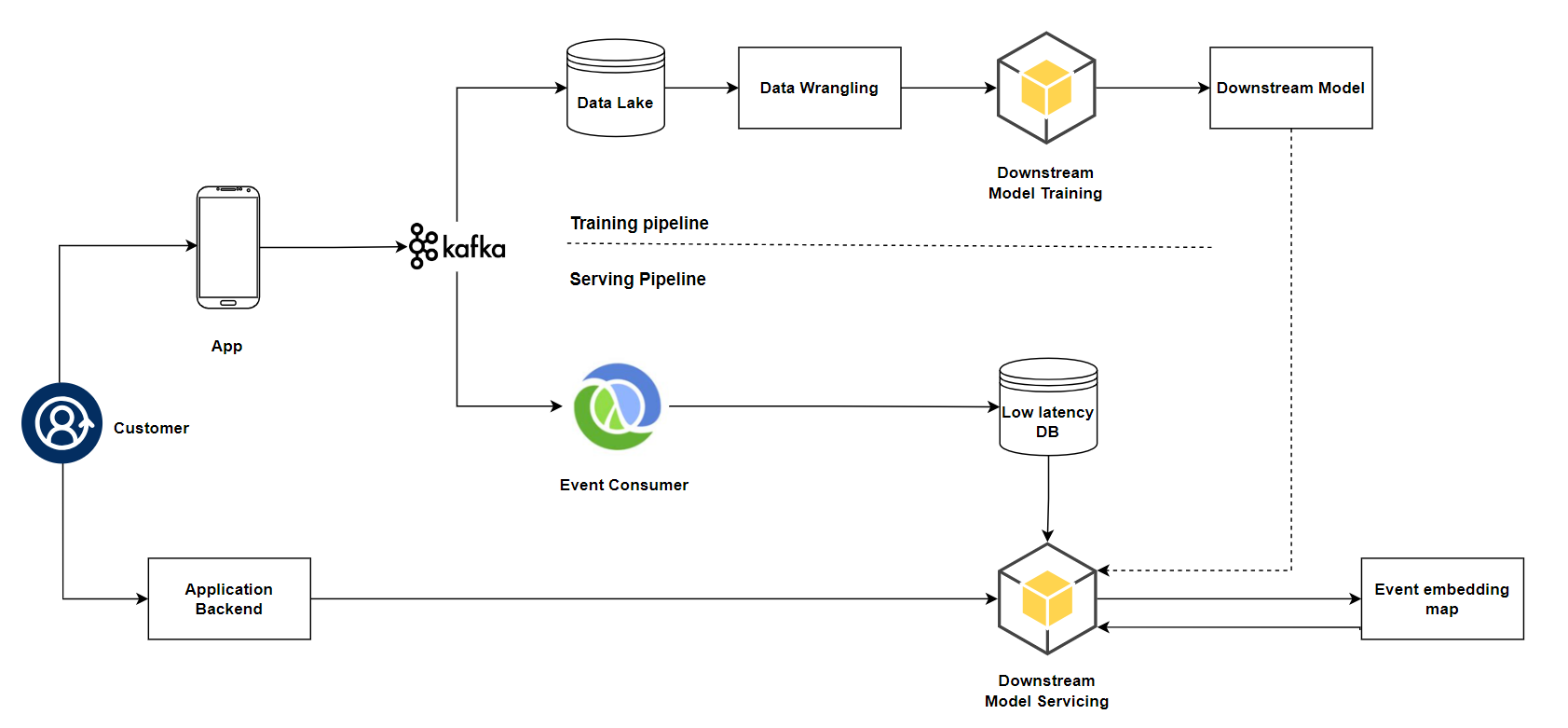
The system architecture of the solution is divided into two main branches: training model and serving model to address the specific problem of customized tutorials. The output of the training branch is a downstream model that has been fully trained with a high degree of accuracy, ready to be employed in the process, and the output of the serving branch is an event embedding that represents the predicted value of the user's familiarity with the technology. The output of the Downstream Model serving becomes the input of the downstream model to perform suggestions compatible with the user's needs.
Kafka, an Event Streaming Platform, is proposed for use because it is suitable for large, complex systems, handling large amounts of data, and its ability to integrate with diverse environments. Additionally, Clojure Multimethods are also proposed for handling customer event data.
Challenge
- Tutorials pop up as users visit apps or website at the first time: because tutorials usually appear when users first enter apps or websites, at a time when they have not yet taken any meaningful actions.
The solution to this challenge is to establish a clear rule: when a user has completed 5-10 actions, a customized tutorial will be triggered to appear, while initially, when a user first accesses the app or website, a brief instruction or overview will be displayed, and the user only needs to click the "Skip" button once.
- Data storage costs: The large amount of data required to train and ensure the accuracy of the model is a significant cost factor, making data storage a challenge and a potential limitation of this solution.
- Model retraining: To ensure accuracy and bridge the gap between predicted results and actual user trends, it is essential to retrain the models at a relevant frequency.
Apply models
The following flowchart illustrates the process of personalizing the user experience on the app and website through suggested Customized Tutorials:
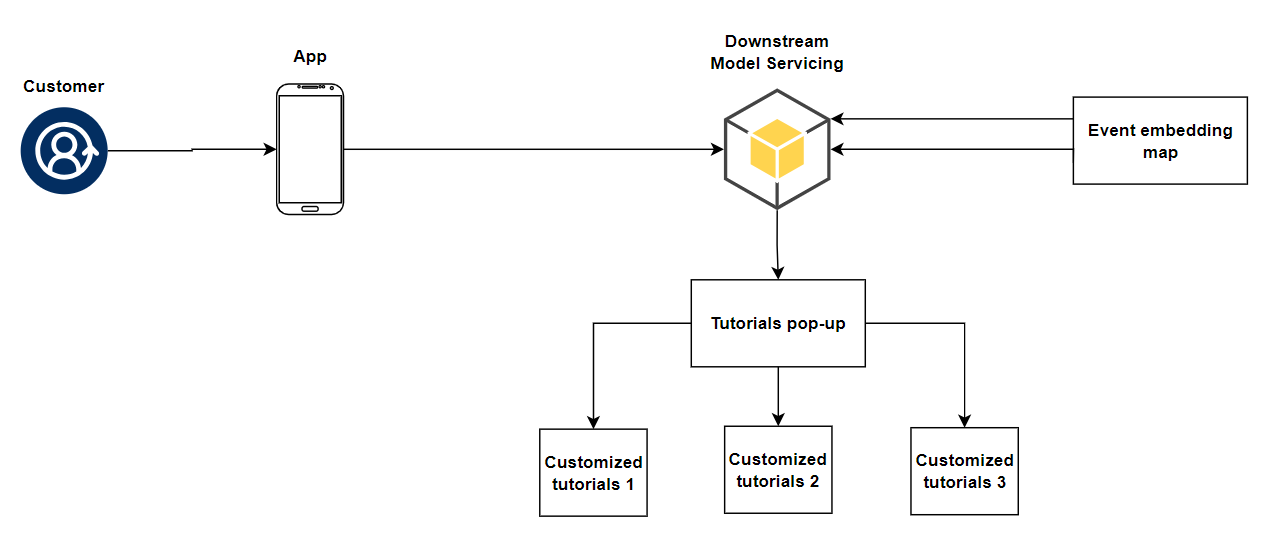
The output of the Contrastive Learning model, which predicts the degree of user familiarity with technology, is an event embedding map. This event embedding map is then used as input to the model to generate customized tutorials that are aligned with the user's level of technical knowledge and expertise.
Conclusion
The "Personalized Tutorials" mock-project was undertaken with the primary objective of developing skills of problem-solving and innovative solutions building to enhance product features with a UX-centric approach. Upon completing this mock-project, I reflect myself on the following key takeaways:
- Contrastive Learning Model Effectiveness: Contrastive learning is a powerful self-supervised learning model, well-suited for working with diverse data types to deliver high-accuracy predictive results. Consequently, the models and techniques proposed in this project have a high potential for real-world application.
- System Architecture Versatility: The system architecture designed in this project exhibits high adaptability, capable of integrating with diverse environments.
- Project Limitations and Future Directions: Due to data constraints, this project was limited to framework development and model proposal, with training, testing, and improvement phases to be executed in future projects with better resource allocation.
